作者在银行做了两年的数据分析和发掘工作,较少打仗互联网的应用场景,因此,不绝都在思索一个题目,“互联网和金融,在数据发掘上,毕竟存在什么样的区别”。在对这个题目的探索和明白过程中,他发现数据发掘自己包罗许多条理。而且模子自己也是存在传统和时髦之分的。
( U% r% T6 A( N$ {- n# s; E & s' C) X) b Y) s & s' C) X) b Y) s
. G% ]8 C/ |8 L# M
一、数据发掘的条理 3 W$ M; C6 T# _( v
不绝想整理下对数据发掘差别条理的明白,这也是这两年多的时间内里,和许多金融范畴、互联网做数据相干工作的小搭档,谈天交换的一些整理和归纳。大概可以分为四类:
) g8 k1 o5 ~# A% q4 a4 N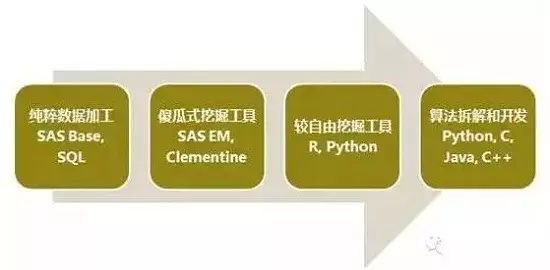
3 u' v0 S/ U: a5 u4 ~; m9 h) ~% h/ S. D9 h
(一)纯粹的数据加工$ d6 r D5 e1 t' _3 U
偏重于变量加工和预处理处罚,从源体系或数据堆栈,对相干数据举行提取、加工、衍生处理处罚,天生各种业务表。然后,以客户号为主键,把这些业务表整合汇总,终极可以拉出一张大宽表,这张宽表就可以称之为“客户画像”。即,有关客户的许多变量和特性的聚集。3 F# a) z! j$ j& w$ F+ @! x7 C
在这个阶段,重要的数据加工工具为SQL和SAS base。
( B' A8 _% N+ p(二)傻瓜式的发掘工具0 B4 J7 A, y1 H0 u2 h4 s
较为典范的就是SAS EM和clementine,内里嵌入许多较为传统成熟的算法、模块和节点(比方逻辑回归、决定树、SVM、神经网络、KNN、聚类等)。通过鼠标的托拉拽,流程式的节点,根本上就可以实现你发掘数据的需求。
8 @" _3 ^- |2 @6 o傻瓜式操纵的长处就是使得数据发掘,入手非常快,较为简单。但是,也存在一些缺陷,即,使得这个发掘过程变得有点单调和无趣。没办法批量运算模子,也没办法开辟一些个性化的算法和应用。用的比力纯熟,而且想要进一步提拔的时间,发起把这两者扬弃。
4 `4 Y2 C2 U( b; h& }. s7 C(三)较为自由的发掘工具
8 t9 \3 Y, ^0 a1 l/ m较为典范的就是R语言和Python。这两个发掘工具是开源的,前者是统计学家开辟的,后者是盘算机学家开辟的。 Z/ ^& [5 `: ?, Z3 T+ S
一方面,可以有许多成熟的、前沿的算法包调用,别的一方面,还可以根据自己的需求,对既有的算法包举行修改调解,顺应自己的分析需求,较为机动。别的,Python在文本、非结构化数据、社会网络方面的处理处罚,功能比力强盛。
% j% Q% @* J* W! z; O2 N(四)算法拆解和自行开辟
/ H- E9 i0 E' q [一样平常会利用Python、C、C++,自己重新编写算法代码。比方,通过自己的代码实现逻辑回归运算过程。乃至,根据自己的业务需求和数据特点,更改此中一些假定和条件,以便进步模子运算的拟合结果。尤其,在生产体系上,通过C编写的代码,运行速率比力快,较易摆设,可以或许满意及时的运算需求。) A* u6 h" e; L5 S Q: @
一样平常来说,从互联网的雇用和对技能的需求来说,一样平常JD内里要求了前三种,如许的职位会被称为“建模分析师”。但是如果增长上了末了一条,如许的职位大概就改称为“算法工程师”。
$ t) r- Y2 d" j) |2 k8 p) L二、模子的明白:传统的和时髦的
' Y7 x' t* v7 p( l据明白,模子应该包罗两种范例。一类是传统的较为成熟的模子,别的一类是较为时髦风趣的模子。对于后者,各人会表现出更多的爱好,一样平常是代表着新技能、新方法和新思绪。) a$ W6 A) }, b- j
(一)传统的模子
0 r4 u' t& t5 o) V传统的模子,重要就是为了办理分类(比方决定树、神经网络、逻辑回归等)、推测(比方回归分析、时间序列等)、聚类(kmeans、系谱、密度聚类等)、关联(无序关联和有序关联)这四类题目。这些都是较为通例和经典的。
, }& G8 D/ |3 T( o2 A(二)时髦风趣的模子+ W+ V8 s/ Q7 x4 |, x9 K
比力风趣、前沿的模子,大概包罗以下几种范例,即社会网络分析、文天职析、基于位置的服务(Location-Based Service,LBS)、数据可视化等。4 @( X9 ^9 B) ]( ^3 e7 v
它们之以是比力时髦,大概的缘故原由是,采取比力新奇前沿的分析技能(社会网络、文天职析),非常贴近现实的应用(LBS),大概是可以或许带来更好的客户体验(数据可视化)。
" V$ }4 ]1 y$ Z# ]0 D- c! d, m , `( i, {4 J" V , `( i, {4 J" V
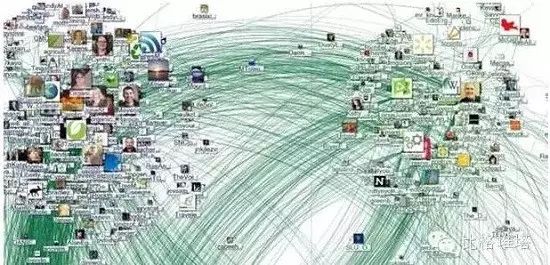
% ^9 `5 n1 R4 {# d& b# m(1)社会网络的应用5 g& Z1 D' N6 b
传统的模子将客户视为单一个体,忽视客户之间的关系,基于客户的特性创建模子。社会网络是基于群体的,偏重研究客户之间的关联,通过网络、中心度、接洽强度、密度,得到一些非常风趣的结果。典范的应用,比方,关键客户的辨认、新产物的排泄和扩散、微博的传播、风险的感染、保险或名誉卡网络团伙敲诈、基于社会网络的保举引擎开辟等。! K- W8 O0 M9 ~
1 V- q! J4 Z" V1 E2 L
3 b/ A" {5 v" D3 ?(2)文本发掘的应用
% ^/ z5 W" v. r' ~# R文本作为非结构化数据,加工分析存在肯定的难度,包罗怎样分词、怎样判定多义词、怎样判定词性,怎样判定感情的猛烈水平。典范的应用,包罗搜索引擎智能匹配、通过投诉文本判定客户感情、通过舆情监控品牌荣誉、通过涉诉文本判定企业策划风险、通过网络爬虫抓取产物品评、词云展示等。
* h3 c3 Y' P1 D0 }关于文天职析,迩来朋侪圈有篇分享,很故意思,号称可以让你刹时酿成墨客。原理很简单,就是先把《全宋词》分词,然后统计频数前100的词语。然后你可以随机凑6个数(1-100),如许就可以拼集出两句诗。比如,随机写两组数字,(2,37,66)和(57,88,33),对应的词语为(东风、无人、黄花)和(干瘪、彻夜、风月)。构成两句诗,即“东风无人黄花落,干瘪彻夜风月明”。还真像那么一回事,有爱好可以玩一玩。7 K+ H, ~4 l$ [
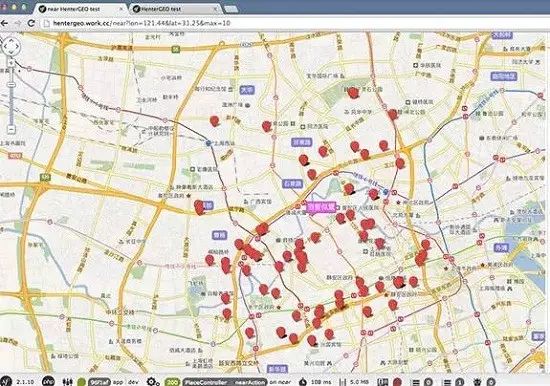
(3)LBS应用
9 L0 C5 `# N0 D( S即基于位置的服务,即怎样把服务和用户的地理位置联合。当下的APP应用,如果不能很好地和地理位置联合,许多时间很难有繁茂的生命力。典范的APP,比方大众点评(餐饮位置)、百度舆图(位置和路径)、滴滴打车、微信位置共享、韶光网(影戏院位置)等服务。别的,银行实在也在研究,怎样把线上客户推送到隔断客户迩来的网点,完成O2O的完善对接,从而带来更好的客户体验。& F; g2 q; d) P" J! i! X7 j5 y! l4 n
 : h4 H3 g# M( T" j. y* C* ~ : h4 H3 g# M( T" j. y* C* ~
! d* m p( N; U; c& b; `/ W/ y
(4)可视化应用
3 s* x- {6 @& |( m; n. i! B% x6 {基于舆图的一些可视化分析,比力热门,比方,春节生齿迁移图、微信生动舆图、人流热力图、拥堵数据的可视化、社会网络扩散可视化等。
! ~- \( w3 D$ j! m, n6 {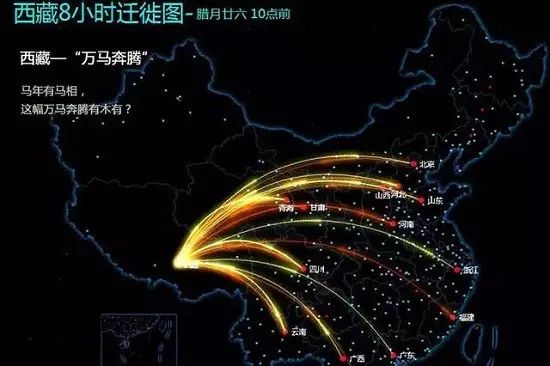 $ z# ~6 r6 u x3 L O $ z# ~6 r6 u x3 L O
) Y4 W- J& x( r) F, u) u2 z* B如果你想让你的分析和发掘比力吸引眼球,请只管往以上四个方面靠拢。
/ c: U+ K! k0 q+ r) }& W三、互联网和金融数据发掘的差别
" u$ w1 n- s% x5 v2 w& E0 J2 m博士后两年,对银行范畴的数据发掘有些根本的相识和认识,但是面对众多的数据范畴,也只能算刚刚入门。许多时间,会很好奇互联网范畴,做数据发掘毕竟是什么样的形态。% g/ S& ^# N( m% i
很早之前,就曾在知乎上提了个题目,“金融范畴的数据发掘和互联网中的数据发掘,毕竟有什么的差别和差别”。这个题目挂了几个月,虽有寥寥的回复,但是没有得到想要的答案。- l% H+ s. _. m3 L: A
既然没人可以或许提供想要的答案,那就,我根据自己的明白、一些场所的碰鼻、以及和一些互联网数据小搭档的打仗,试图归纳和回复下。应该有以下几个方面的差别。 e. j0 h! M& y3 f T6 p2 X
 7 Z/ k: h+ _& r5 ~" d 7 Z/ k: h+ _& r5 ~" d
* j) |% W4 [% h( i6 e/ \! y
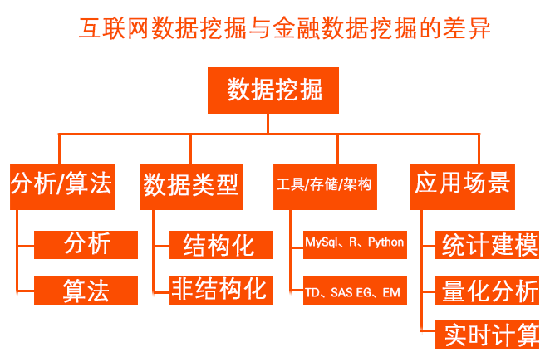
(一)“分析”和“算法”! g2 N$ L# G$ W, O
在互联网中,“分析”和“算法”,分得非常开,对应着“数据分析师”和“算法工程师”两种脚色。前者更多偏重数据提取、加工、处理处罚、运用成熟的算法包,开辟模子,探索数据中的模式和规律。后者更多的是,自己写算法代码,通过C或python摆设到生产体系,及时运算和应用。/ x9 D0 X2 h- j5 H' B
在银行范畴,根本上,只能看到第一种脚色。数据根本上泉源于堆栈体系,然后运用SQL、SAS、R,提取、加工、建模和分析。/ x) G$ [3 v$ z, @( ]2 P: K
(二)数据范例
/ {& f; S& R) i; _数据范例,重要包罗“结构化”和“非结构化”两类数据。前者就是传统的二维表结构。一行一条记载,一列一个变量。后者包罗文本、图像、音频、视频等。
$ D1 I: |. d! @2 k银行内里的数据,更多的是结构化数据,也有少量的非结构化数据(投诉文本、贷款审批文本等)。业务部分对非结构化数据的分析需求比力少。因此,在非结构化数据的分析建模方面,稍显不敷。
0 f3 R2 r7 u" |# ]8 C" U互联网,更多的是网络日记数据,以文本等非结构化数据为主,然后通过肯定的工具将非结构化数据变化为结构化数据,进一步加工和分析。
2 B* M! q0 S/ [( c1 v+ `% l. V(三)工具、存储和架构
6 g; d3 N, Z: j6 ^0 r互联网,根本上是免费导向,以是常常选择开源的工具,比方MySql、R、Python等。常常是基于hadoop的分布式数据收罗、加工、存储和分析。
; v3 q6 L$ T& M商业银行一样平常基于成熟的数据堆栈,比方TD,以及一些成熟的数据发掘工具,SAS EG和EM。4 f+ v" D! w: W" U% _! w; {
(四)应用场景
/ f) B P- D0 H! J在应用场景上,两者之间也存在着非常大的差别。7 x$ C" f3 L2 H( k5 s' G/ y" `8 I( Y
(1)金融范畴4 u( t& F% X+ i& l# [2 l1 N: D7 ]
金融范畴的数据发掘,差别的细分行业(如银行和证券),也是存在差别的。
' m$ E) g: w) X; X% b$ z: I银行范畴的统计建模。银行内的数据发掘,较为偏重统计建模,数据分析对象重要为截面数据,一样平常包罗客户智能(CI)、运营智能(OI)和风险智能(RI)。开辟的模子以离线为主,少量模子,比方反敲诈、申请评分,对及时性的要求比力高。' c3 C$ v5 t8 c, E
证券范畴的量化分析。证券行业的发掘工作,更加偏重量化分析,分析对象更多的是时间序列数据,旨在从大盘指数、颠簸特点、汗青数据中发现趋势和机遇,举行短期的套利操纵。量化分析的及时性要求也比力高,大概是离线运算模子,但是在生意业务体系摆设后,及时运算,捕捉生意业务事故和生意业务机遇。% d( y3 c/ C; l$ _$ ?
(2)互联网
( g1 k' Q/ s% s5 q5 W, B6 l; ^互联网的及时盘算。互联网的应用场景,比方保举引擎、搜索引擎、广告优化、文本发掘(NLP)、反敲诈分析等,许多时间必要将模子摆设在生产体系,对及时相应要求比力高,必要包管比力好的客户体验。
: T' o) x! z+ ?" a四、数据发掘在金融范畴的典范应用
1 m% S0 J& @* D G8 E别人常常会问,在银行内里,数据发掘毕竟是做什么的。也常常在思索怎样从对方的角度回复这个题目。举几个常见的例子做个表明:7 c2 p- _. F6 W N/ ]2 u) [
 7 y3 ?0 y7 v3 R) w* X 7 y3 ?0 y7 v3 R) w* X
. A9 K8 K5 w( V(一)名誉评分2 R/ u% O4 l9 a5 X( k' q7 s
申请评分。当你申请名誉卡、消耗贷款、策划贷款时,银行是否会审批通过,发放多大规模的额度?这个判定很大概就是申请评分模子运算的结果。通过模子盘算你的还款本领和还款意愿,综合评定放款额度和利率水平。; w2 b( E% p- a% E( I, a# y! e
运动评分。当你名誉卡利用一段时间后,银行会根据你的刷卡运动和还款记载,通过运动评分模子,判定是否给你调解固定额度。
4 n: m& O' j8 N- w0 W(二)个性化产物保举3 N" u9 ]1 `& \2 `0 M
许多时间,你大概会收到银行推送的短信大概接到银行坐席的外呼,比如,向你保举某款理产业物。这背后,很大概就是产物相应模子运算的结果。银行会通过模子,盘算你购买某款理产业物的概率,如果概率比价高的话,就会向你推送这款理产业物。
y% p! L0 V9 ?; ?: S5 W* y+ N" p别的,许多时间,差别的客户,银行会个性化的保举差别的产物,很大概就是产物关联分析模子运算的结果。9 F( [1 h/ g3 m( x! ?8 M0 B* J
(三)个性化广告展示
1 D0 Y/ O. P4 R登岸商业银行网站时,通常会有一个广告banner,banner上会展示多少幅广告。许多时间,差别的客户登岸网站,会打仗到差别的广告,即个性化的广告推送。一样平常来说,背景颠末盘算,会判定,你对哪几款广告和产物感爱好,末了推送3-5款你最感爱好的产物,从而可以或许有效吸引你的注意,促进点击、转化和成交。' j/ ^) k/ {: q& G9 P
作者:周学春 |  |手机版|Archiver|
( 桂ICP备12001440号-3 )|网站地图
|手机版|Archiver|
( 桂ICP备12001440号-3 )|网站地图

 发表于 2019-6-13 00:44:34
发表于 2019-6-13 00:44:34